【演算法破解 Ep.1】讚、留言、轉發,誰才是流量老大?(附 Python 原始碼 + 數據)
Threads 演算法破解實錄!到底是騙讚有用,還是轉發有效?我們用 Python 實測相關性熱圖,數據顯示「轉發」的影響力竟然墊底?內文公開實測結果,並附上完整程式碼與原始數據集下載,教你用數據科學找出真正的流量密碼。
Threads 玩久了,大家心裡都有個疑問:到底是騙讚有用,還是騙留言有用?網路上各派說法都有,但很多都是憑感覺,或者是去年的舊聞。
演算法是會變的。為了確保測試結果緊貼 Threads 最新的演算法機制,我不談玄學,直接抓了 2026 年 1 月剛剛出爐、整整 10 萬筆的數據。
我用這筆數據,透過 Python 畫了一張相關性熱圖 (Correlation Heatmap)。結果跟我想的有點不一樣,特別是「轉發」的數據表現,狠狠打臉了一些流傳的說法。
這是【演算法破解】系列的第一篇。文末附上了原始數據集,你也可以下載回去自己跑跑看。
為什麼要看熱力圖?
簡單說,我們想知道誰跟「觀看數(曝光)」的關係最鐵。
統計上的相關係數(Correlation)就是幹這件事的。數值越接近 1,代表兩者連動性越強;接近 0 就代表毫無關係。只要圖畫出來,看顏色深淺,馬上就能知道哪個指標(讚、留言、轉發)最能帶動流量。
實戰:用 Python 畫一張不騙人的圖
我們用 Python 的 Seaborn 套件來畫圖。程式碼不長,但有個細節很關鍵:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
# 1. 讀取數據
df = pd.read_csv("202601291943.csv")
# 2. 選取欄位
cols = ["讚", "回覆", "轉發", "觀看"]
# 3. 計算相關係數
# 重點:這裡用 'spearman' 而不是預設的 'pearson'
# 因為社群數據通常是長尾分佈(少數爆文,多數掛蛋),用 spearman 才準
corr_matrix = df[cols].corr(method="spearman")
# 4. 畫圖
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix,
annot=True,
cmap="YlGnBu",
linewidths=0.5)
plt.yticks(rotation=0)
plt.title("相關性熱圖: 哪些因素會影響觀看次數?")
plt.savefig("correlation_heatmap.png", dpi=300, bbox_inches="tight")
plt.show()特別說明: 注意第 3 步。很多教學會直接用預設算法,但在社群媒體上,一篇爆文的數據可能是普通貼文的幾千倍。這種極端值會讓普通算法失準,所以我們改用 Spearman(等級相關),這樣分析出來的結果才比較符合真實體感。
數據解讀:殘酷的真相
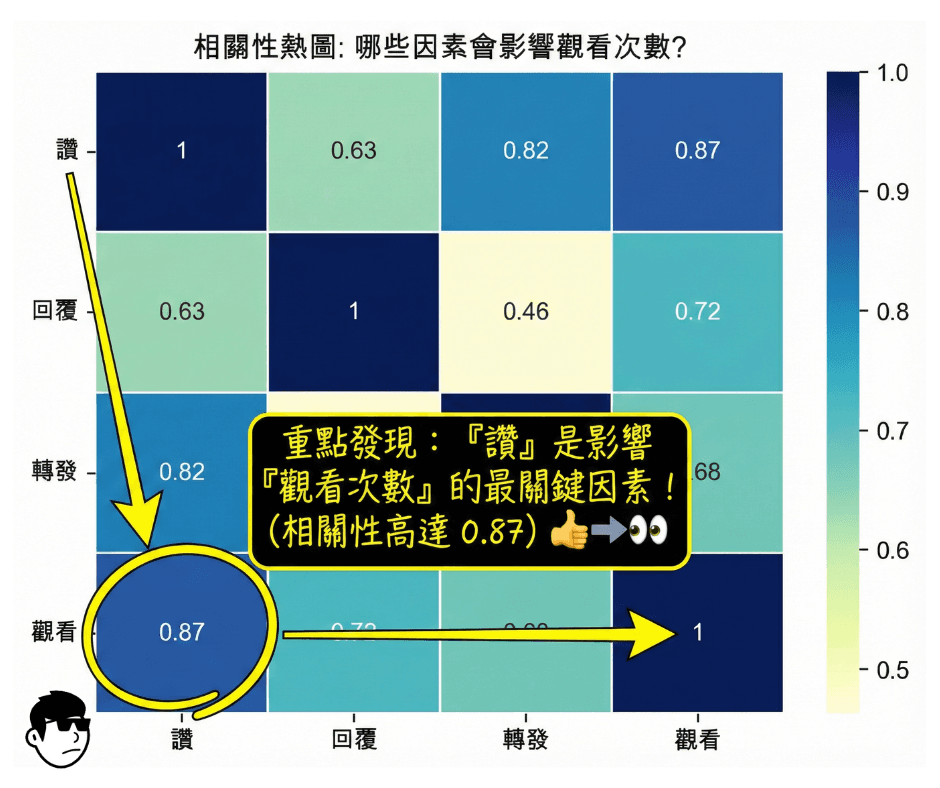
數據跑完,我們得到了這張圖:

這張圖直接點出了三個事實:
讚 vs 觀看 (0.87): 相關性最高。這解釋了為什麼很多單純的「共鳴文」或「廢文」流量這麼大。按讚成本最低,用戶最願意給,而這個動作跟曝光的連動性最強。
回覆 vs 觀看 (0.72): 有影響,但沒那麼神。這打破了「留言才是流量密碼」的迷思。留言確實能增加黏著度,但單純論「把貼文推出去」的力道,還是輸給按讚。
轉發 vs 觀看 (0.68): 這是最讓我意外的。轉發的相關性竟然墊底。這可能意味著,雖然轉發能觸及同溫層外的人,但演算法給予轉發的權重(或是轉發帶來的實際流量效應),其實不如我們想像中那麼大。
給經營者的建議
別想太複雜,先求讚: 讓用戶願意點下愛心,是推動演算法的第一步。簡短、好笑、引發共鳴的內容,往往比長篇大論更有效。
轉發隨緣: 數據顯示轉發跟曝光的關係沒有你想的那麼「鐵」。不要為了求轉發而把內容做得太生硬。
10 萬筆數據集下載
想要驗證我的說法?或是想拿去跑其他的分析?這裡提供這次測試用的完整數據集。
數據規格:
時間: 2026 年 1 月(最新演算法環境)
數量: 100,000 筆中文串文數據
內容:各串文發文後約24小時數據快照
下一集做什麼?
熱力圖只能看「相關性」,不能看「因果」。 是讚多所以觀看多?還是觀看多所以讚多?光看這張圖無解。
下一篇,我們換個工具。我會用機器學習裡的「隨機森林 (Random Forest)」建立一個預測模型,讓 AI 來告訴我們,在它的邏輯裡,哪個特徵的重要性才是真正的老大。

